



Anthropic dropped Claude Opus 4.7 on April 16, 2026. And this time, the benchmarks are hard to argue with.
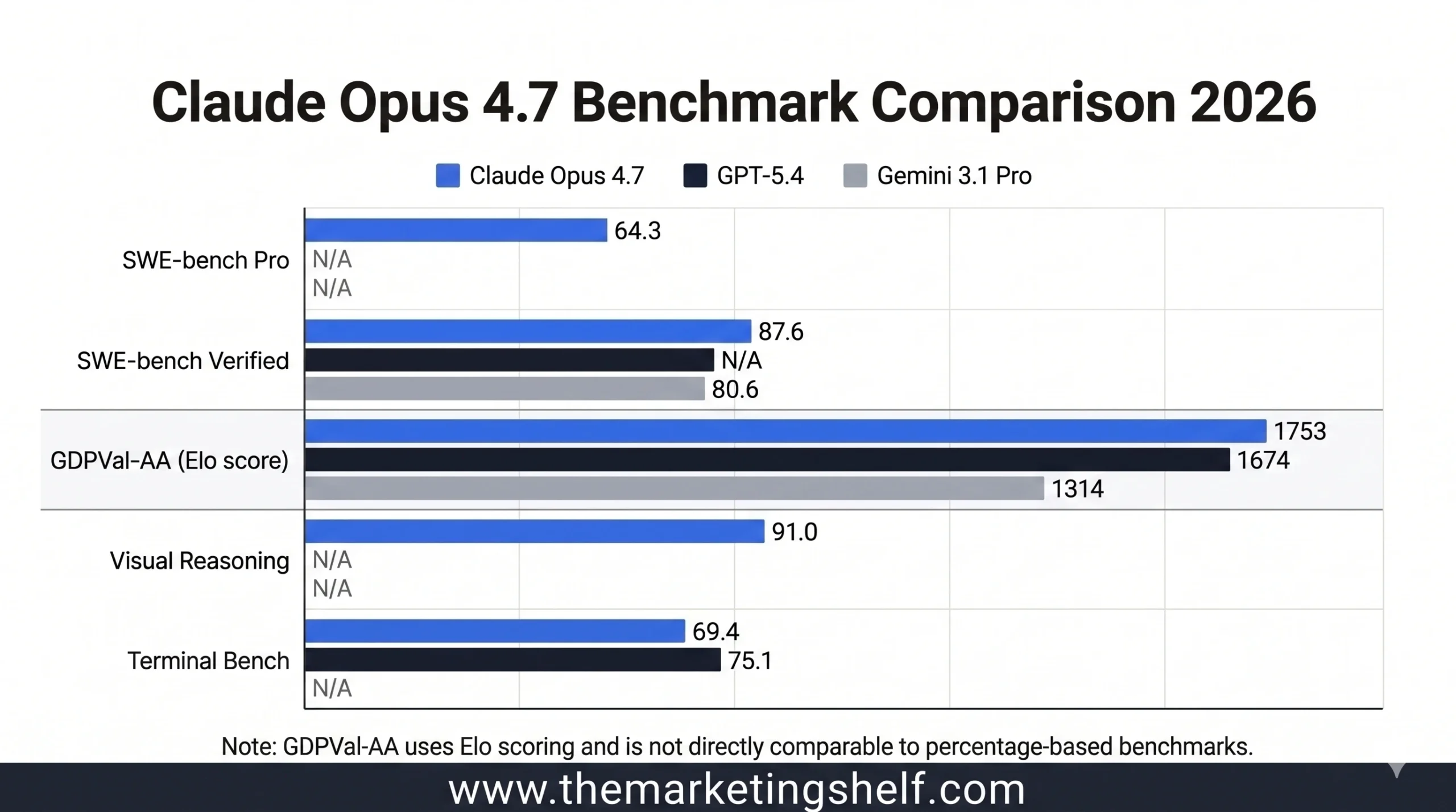
64.3 percent on SWE-bench Pro. 98.5 percent visual acuity in computer use. A 13 percent lift on coding benchmarks over Opus 4.6. Knowledge work Elo of 1,753 beating GPT-5.4’s 1,674 by a meaningful margin.
Those are not incremental numbers. They represent a focused, specific upgrade that solves the exact problems that made developers frustrated with Opus 4.6 in the months before release. For broader context on how Claude compares with GPT and Gemini overall, I’ve broken that down separately here.
But here is the honest version of this review, the kind that does not just paste benchmark tables and call it analysis. Opus 4.7 is a genuine step forward in the areas it targets coding, vision, and long-horizon agentic tasks. It is not a complete sweep. GPT-5.4 still leads on agentic search and multilingual tasks. And the new instruction-following behavior will break some of your existing prompts.
This review covers everything. The real benchmark data. What actually changed under the hood. What enterprise users are reporting from early testing. Where Opus 4.7 loses to competitors. The pricing and whether the math works. And a direct answer to the question everyone is actually asking: should you switch from Opus 4.6 right now?
What Is Claude Opus 4.7?
Claude Opus 4.7 is the latest flagship model from Anthropic, released for general availability on April 16, 2026. It is the most capable Claude model currently available to the public with one important caveat. Anthropic’s most powerful model overall is Claude Mythos Preview, which remains restricted to select enterprise partners as part of Project Glasswing, Anthropic’s cybersecurity safety initiative. Opus 4.7 is what the rest of us get to work with.
The model is available across all Claude plans Pro, Max, Team, and Enterprise as well as through the Claude API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. Pricing is unchanged from Opus 4.6 at five dollars per million input tokens and twenty-five dollars per million output tokens, with up to 90 percent savings available through prompt caching and 50 percent through batch processing.
To access it via the API, the model string is claude-opus-4-7.
Claude Opus 4.7 Benchmarks the Full Picture
This is where most reviews get lazy and just repost Anthropic’s official table. I want to give you the complete picture including where Opus 4.7 wins, where it does not, and what the numbers actually mean in practice.
Where Opus 4.7 Leads
Agentic Coding SWE-bench Pro: 64.3 percent, up from 53.4 percent in Opus 4.6. This is the most important number in the release for developers. SWE-bench Pro tests autonomous resolution of real-world multi-language engineering tasks. The 10-point jump is not marginal it means the model can now handle tasks that previously required multiple human interventions or fell apart completely.
SWE-bench Verified: 87.6 percent versus 80.8 percent in Opus 4.6. This puts Opus 4.7 ahead of Gemini 3.1 Pro at 80.6 percent on this specific benchmark.
Coding Benchmark Improvement: On Anthropic’s own 93-task benchmark, Opus 4.7 lifted resolution by 13 percent over Opus 4.6. It solved four tasks that neither Opus 4.6 nor Sonnet 4.6 could solve at all.
Visual Acuity for Computer Use: 98.5 percent compared to 54.5 percent in Opus 4.6. That is not a typo. This comes directly from XBOW, one of Anthropic’s early access partners testing the model for autonomous penetration testing workflows. The jump is massive and is the result of a genuine architectural change in how the model processes images.
Knowledge Work GDPVal-AA: Elo score of 1,753, beating GPT-5.4 at 1,674 and Gemini 3.1 Pro at 1,314. This benchmark covers economically valuable knowledge work across finance and legal domains. The margin over GPT-5.4 is real.
Graduate-Level Reasoning GPQA Diamond: 94.2 percent, maintaining parity with top-tier models while improving internal consistency.
Visual Reasoning arXiv Reasoning with Tools: 91.0 percent, up from 84.7 percent in Opus 4.6.
MCP-Atlas Multi-Tool Orchestration: 77.3 percent, best in class. This matters specifically for developers building agentic pipelines that use multiple tools.
HWhere Opus 4.7 Does Not Lead
Agentic Search: GPT-5.4 scores 89.3 percent versus Opus 4.7’s 79.3 percent. If your primary use case involves agentic search having the model find, retrieve, and act on web information autonomously GPT-5.4 still has a meaningful advantage here.
Terminal-Based Coding: GPT-5.4 scores 75.1 percent versus Opus 4.7’s 69.4 percent on Terminal-Bench 2.0. For raw terminal coding workflows, the gap is real.
Multilingual Tasks: Gemini 3.1 Pro leads on multilingual question and answer benchmarks. If you work primarily in non-English languages, this is relevant context.
The Number That Tells the Real Story
For marketers specifically, the GDPVal-AA benchmark is the one to focus on. It measures performance on the kinds of knowledge work tasks that marketing professionals actually do financial analysis, document reasoning, structured research, strategy work. Opus 4.7 leads this benchmark with an Elo of 1,753, a gap of 79 points over GPT-5.4. That gap translates directly into better strategic outputs, fewer corrections, and more reliable analysis.
The 5 Features That Actually Change What You Can Do
1. 3x Better Vision – 2,576 Pixel Image Processing
This is the single most practically significant change in Opus 4.7, and it is not getting enough attention in most reviews.
Previous Claude models processed images up to roughly 700 pixels on the long edge. Opus 4.7 raises that ceiling to 2,576 pixels approximately 3.75 megapixels which is more than three times the resolution of any prior Claude model.
The practical consequences are significant. Dense spreadsheets that used to produce unreliable extractions now work reliably. Technical diagrams with fine detail can be read accurately. Screenshots of complex dashboards or interfaces no longer lose critical information in processing. The XBOW benchmark result of 98.5 percent visual acuity versus 54.5 percent for Opus 4.6 reflects this improvement directly.
For marketers, this means you can drop in competitor analytics dashboards, complex campaign reports, or data-heavy slides and get accurate analysis rather than approximations.
2. Adaptive Thinking – The xhigh Effort Level
Opus 4.7 introduces a new effort parameter called xhigh, positioned between the existing high and max settings. This gives you more granular control over the tradeoff between reasoning depth and token consumption.
The practical value: on tasks where you need deep, careful reasoning but max effort is overkill, xhigh delivers a compelling middle ground. Anthropic’s internal data shows that max effort produces the highest scores approaching 75 percent on coding tasks but xhigh provides strong performance with meaningfully lower token cost. For high-volume agentic workflows, this control matters significantly for cost management.
3. Self-Verification Before Responding
One of the most consistent pieces of feedback from enterprise users is that Opus 4.7 “catches its own logical faults during the planning phase.” The model now builds verification steps into its workflow before returning an output, rather than generating a response and leaving error detection to the user.
This behavior is reflected in the Databricks OfficeQA Pro result: 21 percent fewer errors than Opus 4.6 when working with source information. In practice, users at Hex report that Opus 4.7 correctly reports when data is missing instead of providing plausible-but-incorrect fallbacks exactly the behavior that makes AI outputs unreliable in professional contexts.
For marketers using the model for research, analysis, or data interpretation, this matters directly. An AI that tells you it cannot find the answer is far more useful than one that confidently makes up a plausible one.
4. File-Based Memory Across Sessions
Opus 4.7 now uses file system-based memory, meaning it can remember important context and notes across long multi-session workflows. You need to set this up in Claude Code, but once configured, the model carries forward relevant context from previous sessions without requiring you to re-brief it at the start of every task.
For anyone running ongoing agentic workflows continuous content operations, extended development projects, multi-week research tasks this reduces the time-per-session overhead significantly and makes the model more useful as a genuine long-term collaborator rather than a stateless tool.
5. /ultrareview in Claude Code
Opus 4.7 ships with a new /ultrareview command in Claude Code. Unlike standard code reviews that check for syntax errors and obvious bugs, /ultrareview simulates a senior human reviewer flagging subtle design flaws, architectural problems, and logic gaps that would normally require an experienced developer to catch.
Combined with improved instruction-following precision, this makes Opus 4.7 genuinely useful as a code review collaborator rather than just a code generation assistant.
What Real Enterprise Users Are Reporting
Numbers are one thing. What enterprise teams actually experience after deploying a new model is often different from what benchmarks predict. Here is what early access users reported directly to Anthropic.
Quantium: The biggest gains showed up in reasoning depth, structured problem-framing, and complex technical work. Fewer corrections, faster iterations, and stronger outputs on the hardest problems. That matches the benchmark data Opus 4.7 is targeting precisely the complex, multi-step work where Opus 4.6 required the most human supervision.
Hex: Opus 4.7 correctly reports when data is missing instead of providing plausible-but-incorrect fallbacks. Low-effort Opus 4.7 is roughly equivalent to medium-effort Opus 4.6, meaning you get better results without needing to push the model as hard. On their 93-task internal benchmark, resolution lifted 13 percent over Opus 4.6, including four tasks neither Opus 4.6 nor Sonnet 4.6 could solve at all.
XBOW: Visual acuity for computer use went from 54.5 percent to 98.5 percent. For any workflow that depends on the model reading and interacting with visual interfaces, this is a step change, not an incremental improvement.
Databricks: 21 percent fewer errors on OfficeQA Pro when working with source documents. This translates directly to higher reliability in research, analysis, and document-heavy workflows.
Ramp: Stronger role fidelity, instruction-following, and coordination in agent-team workflows. This matters specifically for companies using multiple AI agents working together on complex tasks.
The consistent pattern across all these reports is that Opus 4.7 is reliably better on the hardest, most complex tasks the work that required the most human intervention with Opus 4.6.
The One Thing You Must Know Before Upgrading
This is the warning that most reviews bury or skip entirely: Opus 4.7 follows instructions literally.
Previous models would read between the lines, interpret ambiguous prompts loosely, and fill in reasonable assumptions when instructions were unclear. Opus 4.7 executes the exact text provided. That sounds like an improvement and in most cases it is. Precise instruction-following is generally what you want from a model you’re deploying in production workflows.
The problem is that prompts optimized for Opus 4.6 often relied on the model’s tendency to interpret loosely. A system prompt that worked well because Opus 4.6 would “fill in the gaps” may produce unexpected results with Opus 4.7, which will instead execute precisely what the prompt says even if what it says and what you intended are subtly different.
Anthropic explicitly warns about this in the migration documentation. The recommended approach: run both models in parallel on your real prompts and compare outputs before committing to a full migration. Do not assume outputs will be identical. For teams with heavily optimized Opus 4.6 prompts, the migration is worth doing but it requires careful testing first.
H2: Pricing Does the Math Work?
Opus 4.7 is priced identically to Opus 4.6. Five dollars per million input tokens. Twenty-five dollars per million output tokens. No price increase despite the capability upgrade.
There is one important cost consideration that offset this: Opus 4.7’s updated tokenizer maps the same input to more tokens roughly 1.0 to 1.35 times more depending on content type. The model also thinks more deeply at higher effort levels, particularly on later turns in agentic workflows. This means your actual cost per task will likely be higher than with Opus 4.6, even though the per-token rate is unchanged.
For most use cases, the improved quality of outputs more than justifies the token cost increase. Fewer corrections, fewer failed tasks, and lower error rates mean fewer retries which often offsets the higher per-run token consumption.
The new task budgets feature in the API is worth setting up specifically to manage this. It allows you to set a hard ceiling on token spend for long-running agentic tasks, preventing unexpected costs from particularly deep reasoning sessions.
Claude Opus 4.7 vs GPT-5.4 — The Honest Comparison
This comparison matters because GPT-5.4 is the primary alternative for most teams evaluating frontier models right now.
Opus 4.7 leads on: Agentic coding (SWE-bench Pro: 64.3% vs 61.2%), knowledge work (GDPVal-AA Elo 1753 vs 1674), visual reasoning, multi-tool orchestration, and long-context document analysis.
GPT-5.4 leads on: Agentic search (89.3% vs 79.3%), terminal coding (75.1% vs 69.4%), multilingual tasks, and image generation which remains unavailable in Claude.
The practical decision comes down to what you primarily use the model for. If your work centers on complex analysis, structured reasoning, agentic coding, and knowledge work, Opus 4.7 is the stronger choice. If your workflows depend on real-time web retrieval and agentic search or you work primarily in non-English languages, GPT-5.4 has specific advantages you will notice.
For marketers doing research, content strategy, campaign analysis, and data interpretation, Opus 4.7’s lead on knowledge work is directly relevant. For teams heavily dependent on web search integration in agentic workflows, GPT-5.4’s search advantage is worth considering.
Who Should Upgrade and Who Should Wait
Upgrade Now If:
Your primary work involves complex coding, debugging, or code review. The 13 percent benchmark improvement and /ultrareview command are genuine capability upgrades that will change your daily workflow.
You use the model for document-heavy analysis, financial research, or legal work. The GDPVal-AA benchmark lead directly reflects performance on exactly this kind of knowledge work.
You depend on computer use or visual analysis in your agentic workflows. Going from 54.5 percent to 98.5 percent visual acuity is not a gradual improvement it is a category shift.
You are building multi-agent systems with complex tool orchestration. The MCP-Atlas score of 77.3 percent, best in class, and improved role fidelity in team workflows make Opus 4.7 the right choice for this use case.
Test Before Committing If:
You have heavily optimised system prompts built for Opus 4.6. The literal instruction-following behavior of Opus 4.7 will produce different outputs on prompts that relied on Opus 4.6’s looser interpretation. Run in parallel first.
Your workflows depend primarily on agentic search. GPT-5.4’s 89.3 percent versus 79.3 percent on this specific task type is a meaningful gap.
You work primarily in non-English languages. Gemini 3.1 Pro leads on multilingual performance.
How to Access Claude Opus 4.7
For individual users: Opus 4.7 is available on Claude Pro, Max, Team, and Enterprise plans. Log in to claude.ai and select Opus 4.7 from the model selector.
For developers via the API: Use the model string claude-opus-4-7. The model is available through the Anthropic API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry.
For Claude Code users: The /ultrareview command, auto mode for Max users, and background task execution are all available immediately. Update Claude Code to the latest version to access them.
US-only inference is available at 1.1x pricing for input and output tokens for compliance-sensitive workflows.
If you want to use Claude Opus 4.7 alongside other AI models in a single interface, Merlin AI lets you switch between frontier models including Claude, GPT-5.4, and Gemini from one dashboard.
The Bottom Line
Claude Opus 4.7 is the most capable AI model currently available to the public, with meaningful improvements in the specific areas that matter most for professional and enterprise use.
It leads on knowledge work, agentic coding, multi-tool orchestration, and visual reasoning. It does not lead on agentic search or multilingual tasks. The instruction-following change requires migration care. The token consumption will be higher per task, though the same list price.
For marketers, the case for upgrading is clear. The GDPVal-AA lead, the vision improvements, and the self-verification behavior directly improve the quality of the research, analysis, and content work that marketers use AI for every day.
The bottom line is this: if the hardest tasks in your workflow were exactly the tasks where Opus 4.6 kept letting you down, Opus 4.7 is the model you were waiting for. The benchmark gains are in precisely those places, and the real user reports confirm that the numbers reflect genuine experience, not just evaluation optimization.
FAQs
Q: What is Claude Opus 4.7?
A: Claude Opus 4.7 is Anthropic’s latest flagship AI model, released April 16, 2026. It is the most capable Claude model available to the public, with significant improvements in agentic coding, vision processing, knowledge work, and multi-step reasoning. It is available on Claude Pro, Max, Team, and Enterprise plans, and via the API at the same pricing as Opus 4.6.
Q: How does Claude Opus 4.7 compare to GPT-5.4?
A: Opus 4.7 leads GPT-5.4 on agentic coding (64.3% vs 61.2% on SWE-bench Pro), knowledge work (GDPVal-AA Elo 1753 vs 1674), visual reasoning, and multi-tool orchestration. GPT-5.4 leads on agentic search (89.3% vs 79.3%) and terminal coding. The right choice depends on your primary use case.
Q: What are the biggest improvements in Claude Opus 4.7 over Opus 4.6?
A: The five most significant improvements are: 3x better vision resolution (2,576 pixels vs prior limit), 13% lift on coding benchmarks, visual acuity jump from 54.5% to 98.5% for computer use, new adaptive thinking with xhigh effort level, and self-verification behavior that reduces hallucinations on complex tasks.
Q: Is Claude Opus 4.7 free?
A: Opus 4.7 is available on Claude Pro ($20/month), Max ($100/month), Team, and Enterprise plans. It is not available on the free tier. Developers can access it via the API at $5 per million input tokens and $25 per million output tokens unchanged from Opus 4.6 pricing.
Q: Should I upgrade from Claude Opus 4.6 to 4.7?
A: For most professional and developer use cases, yes. Opus 4.7 is meaningfully better on coding, vision, knowledge work, and complex reasoning. The important caveat: if you have heavily optimised prompts for Opus 4.6, test in parallel first. Opus 4.7 follows instructions more literally than its predecessor, which can produce different outputs on prompts that relied on Opus 4.6’s looser interpretation.


